


 English version
English versionΒΑΣΙΚΕΣ ΕΝΝΟΙΕΣ ΣΤΗΝ ΑΝΑΚΤΗΣΗ ΠΛΗΡΟΦΟΡΙΩΝ
Τι ειναι βαση δεδομενων;
Βάση δεδομένων είναι μια συλλογή από δεδομένα, η οποία υπάρχει με σκοπό να παρέχει πληροφορίες. Αυτά τα δεδομένα μπορεί να είναι βιβλιογραφικές αναγραφές βιβλίων ή άρθρων περιοδικών, μπορεί να είναι στατιστικά στοιχεία εταιριών ή το πλήρες κείμενο άρθρων περιοδικών. Το περιεχόμενο μιας βάσης δεδομένων μπορεί να καλύπτει:
- ένα εξειδικευμένο θεματικό πεδίο π.χ. Bloomsbury Drama Online, Literature Online (LION)
- ή ένα πολύ γενικότερο π.χ. ProQuest Central (ενσωματώνει περίπου 30 βιβλιογραφικές βάσεις, καλύπτει περισσότερα από 160 θεματικά πεδία και ευρετηριάζει περισσότερα από 12.000 περιοδικά με περίπου 9.000 τίτλους πλήρους κειμένου), Ενοποιημένη Μηχανή Αναζήτησης του Α.Π.Θ.
- ή μπορεί να καλύπτει ένα συγκεκριμένο είδος δημοσίευσης π.χ. Εθνικό Αρχείο Διδακτορικών Διατριβών, Conference Proceedings Citation Index - Social Sciences and Humanities (CPCI-SSH), Ψηφιακή Συλλογή Εφημερίδων Εθνικής Βιβλιοθήκης e-φημερίς (1893-1983).
Μπορούμε να κατατάξουμε τις βάσεις δεδομένων σε δύο μεγάλες κατηγορίες:
- Βιβλιογραφικές Βάσεις Δεδομένων
Αποτελούνται από τις ηλεκτρονικές εγγραφές των τεκμηρίων/υλικού που περιλαμβάνουν, οι οποίες περιγράφουν τα συγκεκριμένα τεκμήρια, που συνήθως είναι ανακτήσιμα με το συγγραφέα, τον τίτλο, τα θέματα, τις λέξεις-κλειδιά, την επιτομή και την περίληψη. Ένα καλό παράδειγμα βιβλιογραφικής βάσης δεδομένων είναι ο ηλεκτρονικός δημόσιος κατάλογος μιας βιβλιοθήκης. Για κάθε βιβλίο ή άλλο έγγραφο στη βάση δεδομένων περιλαμβάνονται μια σειρά από πληροφορίες όπως: τίτλος, συγγραφέας, ημερομηνία πνευματικών δικαιωμάτων, θέμα, ταξινομικός αριθμός και ένας μοναδικός αριθμός αναγνώρισης του τεκμηρίου π.χ. ISBN, ISSN, DOI. - Βάσεις Δεδομένων Πλήρους Κειμένου
Μια βάση δεδομένων πλήρους κειμένου περιέχει ολόκληρο το κείμενο μιας πρωτογενούς πηγής πέρα από τη βιβλιογραφικής της περιγραφή. Μια βάση δεδομένων πλήρους κειμένου μπορεί για παράδειγμα να περιλαμβάνει άρθρα περιοδικών, βιβλία, πρακτικά συνεδρίων, εφημερίδες, κ.α.
Βασεις δεδομενων και ευρετηριαση
Υπάρχουν βάσεις δεδομένων που καλύπτουν υλικό μιας συγκεκριμένης ομάδας περιοδικών ή βιβλίων ή διδακτορικών διατριών κ.α. ενώ άλλες προσπαθούν να είναι πλήρεις, συλλέγοντας την παγκόσμια εκδοτική παραγωγή ενός συγκεκριμένου θεματικού πεδίου. Τα τεκμήρια εισάγονται στο σύστημα αφού πρώτα εξετασθούν για τη σχετικότητά τους με το θέμα και το σκοπό για τον οποίο δημιουργήθηκε η βάση, ευρετηριαστούν και γραφούν οι επιτομές τους. Γενικά, το κόστος παραγωγής των βάσεων δεδομένων, βιβλιογραφικών και πλήρους κειμένου, είναι αρκετά μεγάλο επειδή απαιτείται αυστηρή επιλογή και ανάλυση των τεκμηρίων που περιλαμβάνουν.
Κάθε βιβλιογραφική βάση είναι ένα μοναδικό προϊόν που σχεδιάστηκε για να καλύψει τις πληροφοριακές ανάγκες μιας συγκεκριμένης ομάδας χρηστών. Γι’ αυτό το λόγο δεν υπάρχει κάποιο πρότυπο για το περιεχόμενο της εγγραφής μιας βάσης δεδομένων. Συνήθως η εγγραφή περιλαμβάνει ένα κλειδί εγγραφής, βιβλιογραφικές πληροφορίες όπως συγγραφέα, τίτλο, την πηγή του ντοκουμέντου, μια επιτομή και θεματικούς δείκτες όπως όρους ευρετηρίασης ή θεματικές επικεφαλίδες. Στις δε βάσεις πλήρους κειμένου συμπεριλαμβάνεται και ολόκληρο το κείμενο του ντοκουμέντου.
Οι θεματικές πληροφορίες που περιλαμβάνει μια εγγραφή είναι δύο ειδών: α. οι ονομαζόμενες “φυσική γλώσσα” ή “γλώσσα τεκμηρίου”, οι οποίες βρίσκονται στα πεδία του τίτλου, της επιτομής ή στο πλήρες κείμενο του ντοκουμέντου, β. και όροι από ένα ελεγχόμενο λεξιλόγιο, οι οποίοι δίνονται στα τεκμήρια από τους ανθρώπους που κάνουν την ευρετηρίαση. Οι περισσότερες βάσεις δεδομένων περιλαμβάνουν τους όρους της ευρετηρίασης στο πεδίο του περιγραφέα (descriptor), τους οποίους παίρνουν από κάποιο θησαυρό (π.χ στη βάση PsychoINFO χρησιμοποιείται ο θησαυρός Thesaurus for Psychological Terms). Άλλου είδους κωδικοί ή όροι μπορούν επίσης να χρησιμοποιηθούν αν είναι κατάλληλοι με το θεματικό περιεχόμενο της βάσης (π.χ. οι κωδικοί Historical Time Periods στη βάση δεδομένων Historical Abstracts).
Τα ευρετήρια των διαφόρων βάσεων δεδομένων στοχεύουν να λειτουργήσουν ως υποκατάστατα των τεκμηρίων που περιλαμβάνουν, έτσι ώστε όταν ο ερευνητής θέσει κάποιο ερώτημα χρησιμοποιώντας συγκεκριμένους όρους να είναι δυνατή η ανάκτηση των τεκμηρίων που περιλαμβάνουν τους όρους αυτούς.
Μια γλώσσα ευρετηρίασης είναι η γλώσσα που χρησιμοποιείται για να περιγράψει το θέμα ή άλλες απόψεις του τεκμηρίου σε ένα ευρετήριο. Οι γλώσσες που χρησιμοποιούνται στην ευρετηρίαση είναι δύο:
- Ελεγχόμενη γλώσσα ευρετηρίασης (controlled indexing language),
στην οποία ανήκουν οι καθιερωμένες θεματικές επικεφαλίδες και οι θησαυροί. Οι όροι που είναι αποδεκτοί για να χρησιμοποιηθούν, θεματικοί περιγραφείς, αποτελούν καταστάσεις και χρησιμοποιούνται για την περιγραφή των θεμάτων. - Φυσική γλώσσα ευρετηρίασης (natural indexing language),
είναι η γλώσσα που χρησιμοποιεί τη γλώσσα του τεκμηρίου στις βάσεις δεδομένων πλήρους κειμένου.
Τι ειναι ανακτηση πληροφοριων
Εν συντομία μπορούμε να πούμε ότι η ανάκτηση πληροφοριών περιλαμβάνει τη διαδικασία εντοπισμού κάποιας πληροφορίας που χρειαζόμαστε σε μια αποθήκη πληροφοριών ή σε μια βάση δεδομένων.
Ο Blair έχει πει ότι “το βασικό πρόβλημα στην ανάκτηση πληροφοριών είναι το πως να αναπαραστήσεις τα ντοκουμέντα για ανάκτηση”. Αυτό φαίνεται να έχει αρχίσει να μην ισχύει μια και όλο περισσότερες βάσεις περιλαμβάνουν το πλήρες κείμενο των ντοκουμέντων ενώ πρωτύτερα αποτελούνταν από ένα ευρετήριο ή όρους ευρετηρίασης που αναπαριστούσαν το περιεχόμενο των ντοκουμέντων. Όχι μόνο χρησιμοποιείται η φυσική γλώσσα του κειμένου στις βάσεις δεδομένων αλλά όλο και περισσότερο αρχίζει να χρησιμοποιείται η φυσική γλώσσα σαν μέσο για να δηλώσει ο χρήστης αυτό που θέλει στο σύστημα ανάκτησης πληροφοριών. Αυτό ονομάζεται “ερώτημα = query” και είτε χρησιμοποιείται φυσική γλώσσα είτε κάποια από τις τεχνητές γλώσσες που έχουν δημιουργηθεί για το σκοπό αυτό, η τάση είναι σίγουρα να δημιουργούνται όλο και πιο σύνθετα και εκφραστικά ερωτήματα.
Το κύριο πρόβλημα λοιπόν στην ανάκτηση πληροφοριών έγκειται στο πώς να ταιριάξουμε, να συγκρίνουμε και να συσχετίσουμε την αίτηση του χρήστη για πληροφόρηση με τα ντοκουμέντα που είναι αποθηκευμένα στη βάση δεδομένων. Όπως το έθεσαν οι Liddy, Paik, Yu, και McKenna “Ένα επιτυχημένο σύστημα ανάκτησης πληροφοριών πρέπει να κάνει ανάκτηση με βάση το τι οι άνθρωποι εννοούν με το ερώτημά τους και όχι μόνο με το τι λένε”.
Από την άλλη πλευρά, το ερώτημα μπορεί να θεωρηθεί σαν μια μορφή αναπαράστασης του ντοκουμέντου. Από αυτήν την άποψη μπορούμε να συμφωνήσουμε με τον Blair ότι είναι θέμα μεγάλης σημασίας το πώς να εκφράσουμε με τον καλύτερο δυνατό τρόπο ένα ερώτημα, δηλαδή πώς να αναπαραστήσουμε αυτό που θέλουμε να βρούμε στα ντοκουμέντα.
Συναφεια, Ανακληση, Ακριβεια
Οι πληροφοριακές ανάγκες των χρηστών συνήθως αποτελούνται από σύνθετες έννοιες. Οι τεχνικές αναζήτησης πληροφοριών μας δίνουν τη δυνατότητα να συνδέσουμε μεταξύ τους τους όρους αναζήτησης για να μπορέσουμε να τους συνδυάσουμε με διάφορους τρόπους ώστε να πετύχουμε την ανάκτηση των επιθυμητών εγγράφων.
Η χρήση δύο, τριών ή περισσότερων εννοιών σε μια έρευνα προϋποθέτει τη χρήση κάποιας στρατηγικής αναζήτησης (search strategy). Η στρατηγική αναζήτησης αποτελεί ένα σχέδιο ή μια προσέγγιση για τη λύση ενός προβλήματος αναζήτησης. Η τακτική αναζήτησης (search tactic) είναι μια κίνηση που γίνεται για την επέκταση της έρευνας, ενώ η διατύπωση αναζήτησης (search formulation) είναι οι προτάσεις που εκφράζουν την ερώτηση σε μορφή που να είναι κατανοητή από τη βάση δεδομένων ή το εργαλείο έρευνας.
Σε κάθε αναζήτηση θα ανακτηθούν μια σειρά από εγγραφές που είναι συναφείς ή αλλιώς σχετικές με το θέμα της έρευνας και άλλες που δεν ενδιαφέρουν καθόλου τον ερευνητή. Η έννοια της συνάφειας είναι δύσκολο να οριστεί γιατί βασίζεται στις απόψεις των ερευνητών και στο πως οι ίδιοι αντιλαμβάνονται τις πληροφοριακές τους ανάγκες και ποια τεκμήρια είναι χρήσιμα γι’ αυτούς. Ακόμα κι από αυτές τις εγγραφές που είναι συναφείς, άλλες έχουν άμεση σχέση με το θέμα και άλλες έμμεση. Στην ανάκτηση πληροφοριών ο ερευνητής σπάνια μπορεί να ανακτήσει όλες τις πληροφορίες που χρειάζεται και μόνον αυτές. Τις περισσότερες φορές θα ανακτηθούν πάνω από μια εγγραφή που δεν είναι σχετική με την ερώτηση. Την ίδια στιγμή ο ερευνητής δεν είναι σίγουρος αν μετά το τέλος της έρευνας δεν έχουν μείνει σημαντικές εγγραφές στη βάση δεδομένων που δεν έχουν ανακτηθεί ή αν έχει ανακτήσει τουλάχιστον τις πιο χρήσιμες από τις εγγραφές.
Σχεδόν κάθε έρευνα αναμένεται να περιλαμβάνει ένα ποσοστό συναφών τεκμηρίων και ένα ποσοστό μη-συναφών τεκμηρίων. Ακόμη και όταν ανακτηθούν συναφή τεκμήρια, άλλα σχετικά τεκμήρια και ίσως περισσότερο σχετικά μπορεί να μην ανακτηθούν. Σαν αποτέλεσμα μετά από μια συγκεκριμένη αναζήτηση τα τεκμήρια σε μια βάση μπορούν να ταξινομηθούν σε τέσσερις κατηγορίες.
| Συναφή | Μη Συναφή | |
|---|---|---|
| Ανακτήθηκαν | χ | φ |
| Δεν Ανακτήθηκαν | ψ | ω |
Το ιδανικό θα ήταν να ανακτηθούν όλα και μόνο τα συναφή τεκμήρια και να μην συμπεριληφθούν στο αποτέλεσμα μη σχετικά τεκμήρια. Αυτό όμως είναι πολύ σπάνιο. Εξάλλου ο ερευνητής δε θέλει πάντοτε όλα τα συναφή τεκμήρια από μια βάση δεδομένων. Συνήθως χρειάζεται έναν ικανοποιητικό αριθμό τεκμηρίων που απαντούν στο ερώτημά του ή λύνουν το πρόβλημά του. Αν επιτευχθεί αυτό, δε τους χρειάζονται άλλα τεκμήρια. Ωστόσο υπάρχουν περιπτώσεις που ο ερευνητής χρειάζεται σε βάθος έρευνα π.χ. για τη διδακτορική του διατριβή ή για την υπεράσπιση μιας υπόθεσης στο δικαστήριο. Η έρευνα σε βάθος έχει σχέση και με το μέγεθος της βάσης δεδομένων. Το πόσο εξαντλητική θα είναι η έρευνα και το μέγεθος της βάσης δεδομένων είναι παράμετροι που επηρεάζουν σημαντικά την έρευνα.
Με βάση αυτά τα δύο μεγέθη, μπορούμε να διακρίνουμε τέσσερις διαφορετικές περιπτώσεις αναζήτησης.
| Μεγάλο Σύστημα | Μικρό Σύστημα | |
|---|---|---|
| Εξαντλητική | α | β |
| Μη εξαντλητική | γ | δ |
Η πιο σημαντική έρευνα είναι η περίπτωση της εξαντλητικής έρευνας σε μεγάλη βάση δεδομένων. Ιδιαίτερα σ΄αυτή την περίπτωση είναι απαραίτητο να γίνουν προσπάθειες να αυξηθεί στο μέγιστο η ανάκτηση των συναφών τεκμηρίων και να μειωθεί στο ελάχιστο η ανάκτηση των άσχετων τεκμηρίων. Αυτή η διαδικασία περιγράφεται σαν αύξηση της ανάκλησης (recall) και αύξηση της ακρίβειας (precision). Χρησιμοποιούνται δηλαδή δύο διαστάσεις: η ανάκληση και η ακρίβεια.

Η ανάκληση, λοιπόν, μπορεί να μετρηθεί διαιρώντας τον αριθμό των συναφών τεκμηρίων που ανακτήθηκαν με τον αριθμό των συναφών τεκμηρίων που περιλαμβάνονται σε όλη τη συλλογή.
Όπως είναι κατανοητό η ανάκληση δεν μπορεί να μετρηθεί εύκολα, αλλά μπορεί να υπολογιστεί. Η μέτρηση την ανάκλησης μπορεί να γίνει μόνο σε εργαστήριο. Αντίθετα η ακρίβεια μπορεί να μετρηθεί ακόμη και από τον ίδιο τον ερευνητή.

Η ακρίβεια από την άλλη μπορεί να μετρηθεί διαιρώντας τον αριθμό των συναφών τεκμηρίων που ανακτήθηκαν με τον συνολικό αριθμό των τεκμηρίων που ανακτήθηκαν.
Μπορούμε να υπολογίσουμε την ανάκληση και την ακρίβεια του πίνακα 1 ως εξής:
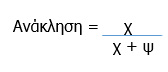
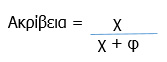
Μετά από πολλές έρευνες που έχουν γίνει σε διάφορα συστήματα ανάκτησης πληροφοριών έχει διαπιστωθεί ότι υπάρχει μια αντίστροφη σχέση ανάμεσα στην ανάκληση και στην ακρίβεια. Αλλάζοντας τη διατύπωση της αναζήτησης, είτε η ανάκληση, είτε η ακρίβεια μπορούν να αυξηθούν, με αποτέλεσμα η άλλη διάσταση να μειωθεί. Για παράδειγμα, προσθέτοντας έναν όρο με το λογικό τελεστή “OR”, συνήθως αυξάνεται η ανάκληση αλλά ταυτόχρονα μειώνεται η ακρίβεια γιατί μαζί με τα συναφή τεκμήρια που θα ανακτηθούν, ανακτώνται και τεκμήρια που δεν είναι συναφή. Αντίθετα, αν προστεθεί ένας όρος με τον τελεστή “AND”, θα μειωθεί ο αριθμός των τεκμηρίων που θα ανακτηθούν ελαχιστοποιώντας τον αριθμό των μη συναφών τεκμηρίων με αποτέλεσμα να μειωθεί η ανάκληση και να αυξηθεί η ακρίβεια.
Το ιδανικό θα ήταν να ισούνται και οι δύο διαστάσεις με το 1.
Να ανακτήσουμε δηλαδή όλα τα συναφή (μέγιστη ανάκληση) και μόνο συναφή τεκμήρια (μέγιστη ακρίβεια).
Δηλαδή, έχουμε μέγιστη ακρίβεια όταν ανακτάμε μόνο συναφή τεκμήρια και μέγιστη ανάκληση όταν ανακτάμε όλα τα συναφή τεκμήρια της συλλογής.
Επειδή αυτό είναι πολύ δύσκολο να συμβεί, αναφερόμαστε στο πως να αυξήσουμε την ανάκληση και την ακρίβεια.
Αύξηση της ανάκλησης: αύξηση στο μέγιστο βαθμό η ανάκτηση των συναφών τεκμηρίων.
Ζητούμενο: να ανακτηθούν όλα τα συναφή/σχετικά τεκμήρια που υπάρχουν στη βάση.
Αύξηση της ακριβείας: μείωση στο ελάχιστο η ανάκτηση άσχετων τεκμηρίων.
Ζητούμενο: να ανακτηθούν μόνο συναφή τεκμήρια
Η αύξηση των δύο διαστάσεων μπορεί να προέλθει και κατά τη διαδικασία την έρευνας. Το αποτέλεσμα μπορεί να ξεκινήσει με χαμηλή ανάκληση, η οποία όμως μπορεί να αυξηθεί κατά τη διαδικασία της έρευνας.
Τα δύο μέτρα, ανάκληση και ακρίβεια δεν είναι τέλεια, αφού θα εξαρτηθούν από τον αριθμό των λογικών αποφάσεων που θα πάρει ο ερευνητής αλλά και από το τι ακριβώς ψάχνει και πόσο εύκολα μπορεί να μείνει ευχαριστημένος από το αποτέλεσμα. Ωστόσο, αποτελούν χρήσιμες θεωρητικές έννοιες αφού μπορούμε να αναφερθούμε σε τρόπους αύξησης και μείωσης π.χ. της ανάκλησης, αν και δεν είμαστε πάντα σε θέση να μετρήσουμε το μέγεθος της αλλαγής. Και οι δύο διαστάσεις χρησιμοποιούνται σε εξαντλητικές έρευνες.
Βιβλιογραφία
Κορομπίλη, Στέλλα. Βιβλιοθηκονομικές Εφαρμογές Ι: Online ανάκτηση πληροφοριών. Σίνδος, 2001.
Baeza-Yates, Ricard, and Berthier Ribeiro-Neto. Modern Information Retrieval. Addison-Wesley/ACM Press, 1999.
Meadow, Charles T., Bert R. Boyce and Donald H. Kraft. Text Information Retrieval Systems. Second ed., Academic Press, 2000.
Stebbins, Leslie F. Student guide to research in the digital age: how to locate and evaluate information sources. Libraries Unlimited, 2006.
Επιμέλεια Οδηγού: Κλεονίκη Σκουλαρίκα
